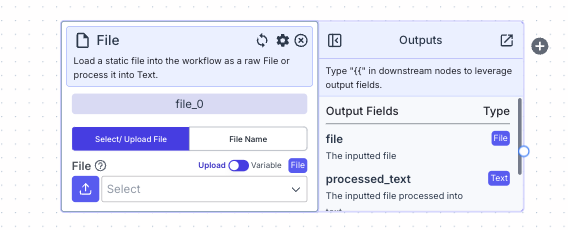
- Upload a file by clicking the upload button
- Use the dropdown to select a previously uploaded file to the VectorShift platform
- If switch the toggle from “Upload” to “Variable”, you can reference files from other nodes
Node Inputs
If Select/Upload File selected:- File: Select an existing file from the platform or upload a file for processing
- Type:
File
- Type:
- File Name: The name of the file from the VectorShift platform from the files tab
- Type:
Text
- Type:
Node Parameters
In the gear:- Processing Model: The model that you want to use to extract the text from the file. The models available are: Default (Basic OCR), Llama Parse and Textract.
- Use default if your files contain primarily text.
- If your files contain complex tables, images, diagrams, etc., use Llama Parse or Textract (Note: additional costs will be charged).
Node Outputs
- File: The raw file, as-is
- Type:
File - Example usage:
{{file_0.file}}
- Type:
- Processed Text: The processed text extracted from the inputted file
- Type:
Text - Example usage:
{{file_0.processed_text}}
- Type:
Considerations
- Click on the “+” button on the right of the node to create and connect the node to a semantic search node to enable semantic search on the file.
Example
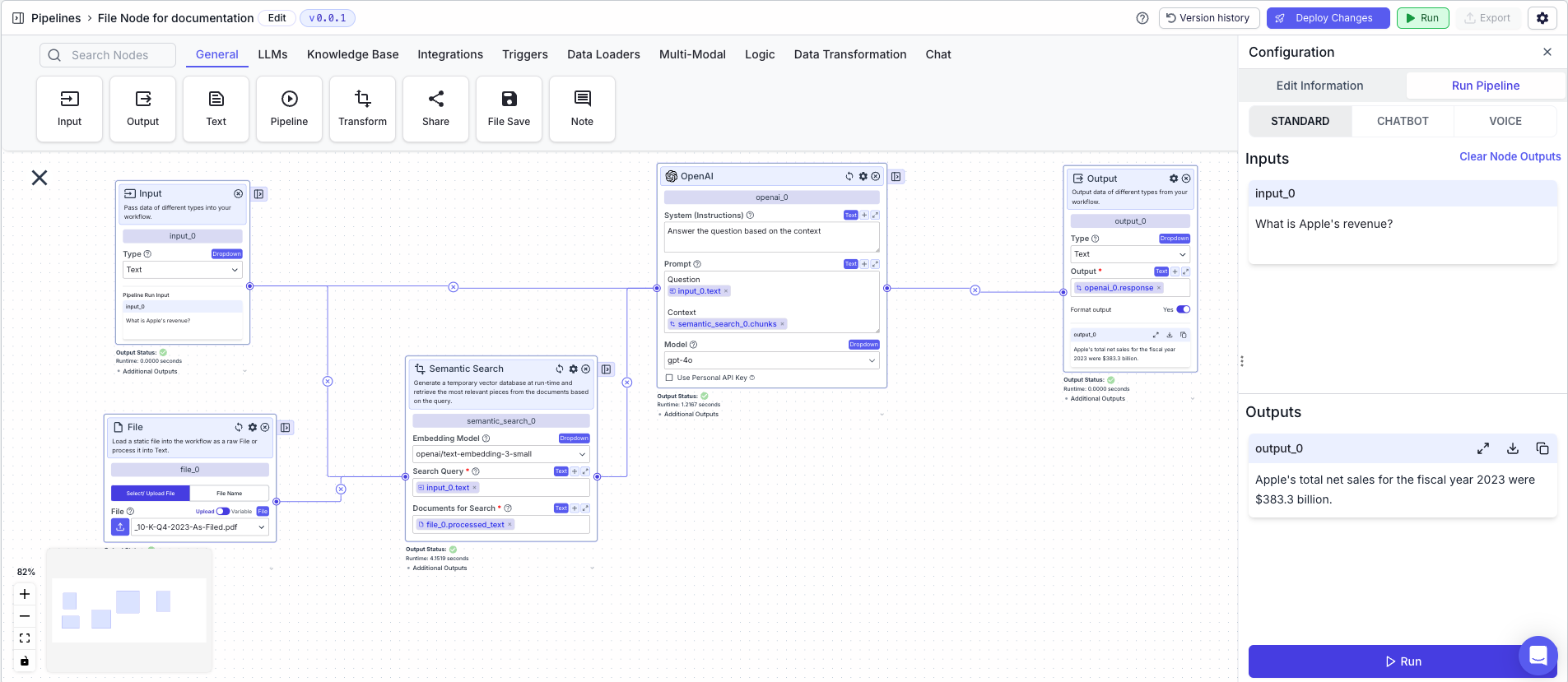
The below example is a pipeline which answers questions about the Apple annual report (10-K).- Input Node: The query about the file.
- File Node: Upload the file by clicking on the purple upload button (in this case the Apple annual report).
- Semantic Search Node: Find semantically similar chunks to a question (input node) based on a file (file node).
- Search Query:
{{input_0.text}} - Documents for Search:
{{file_0.processed_text}}
- Search Query:
- LLM Node: Answer a user query (input node) based on relevant information (semantic search node).
- Prompt:
{{input_0.text}} and {{semantic_search_0.chunks}}
- Prompt:
- Output Node: Display the LLM’s response
- Output
{{openai_0.response}}
- Output