Node Inputs
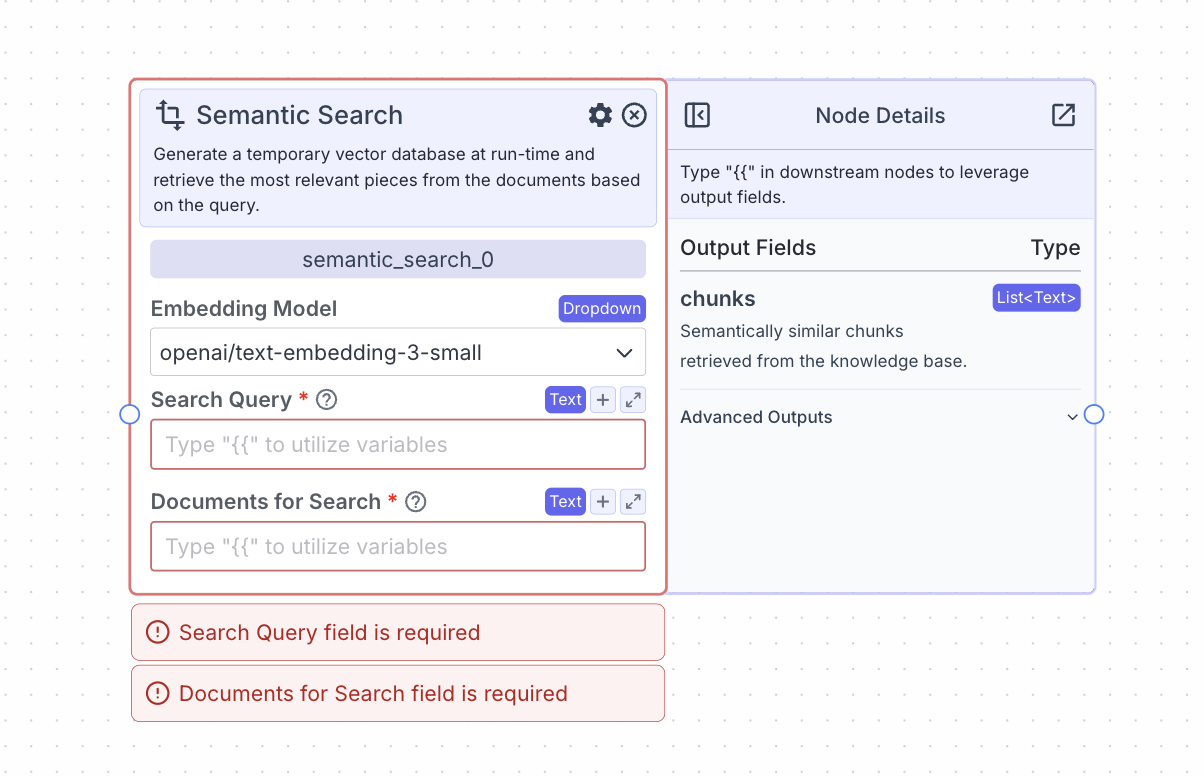
- Search Query: The query that will be used to search the embedded documents semantically for relevant pieces
- Type:
Text
- Type:
- Documents for Search: The text that will be semantically searched
- Type:
Text
- Type:
Node Parameters
On the face of the node:- Embedding model: The embedding model to use to embed the documents
- Type:
Dropdown
- Type:
- Max chunks per query: the maximum number of pieces of data to be returned per query
- Enable Filter: enable the ability to write a metadata filter
- Enable Context: enable a text field to provide additional context for the search query
- Re-rank documents: Performs an additional reranking step to reorder the documents by relevance to the query
- Score Cutoff: The minimum relevancy score (between 0 and 1) that each piece of data will have semantically to the query
- Retrieval Unit: Return the most relevant chunks (text content) or Documents (will return document metadata)
- Transform Query: Transform the query for better results
- Answer Multiple Questions: Extract separate questions from the query and retrieve content separately for each question to improve search performance
- Expand Query: Expand query to improve semantic search
- Do Advanced QA: Use additional LLM calls to analyze each document to improve answer correctness
- Show Immediate Steps: Display the process the knowledge base is conducting at a given time in the chatUI
- Format Context for an LLM: Do an additional LLM call to format output
Node Outputs
If Retrieval Unit is set to Chunks- Chunks: Semantically similar chunks retrieved from the documents
- Type:
List<Text> - Example usage:
{{semantic_search_0.chunks}}
- Type:
- Documents: Metadata for semantically similar documents retrieved from the documents
- Type:
List<Text> - Example usage:
{{semantic_search_0.documents}}
- Type:
- Response: A direct answer to the query
- Type:
Text - Example usage:
{{semantic_search_0.response}}
- Type:
Considerations
- Use a semantic search node when your pipeline loads new data at run time for querying. Use a Knowledge Base Reader node when you want to query previously loaded data that has already been loaded.
- If the semantic search node is not returning relevant information to a query, try increasing the number of max chunks per query in the gear of the knowledge base.
- For debugging purposes, you may attach an output node to the semantic search node to view the chunks that are returned for the query.
Example
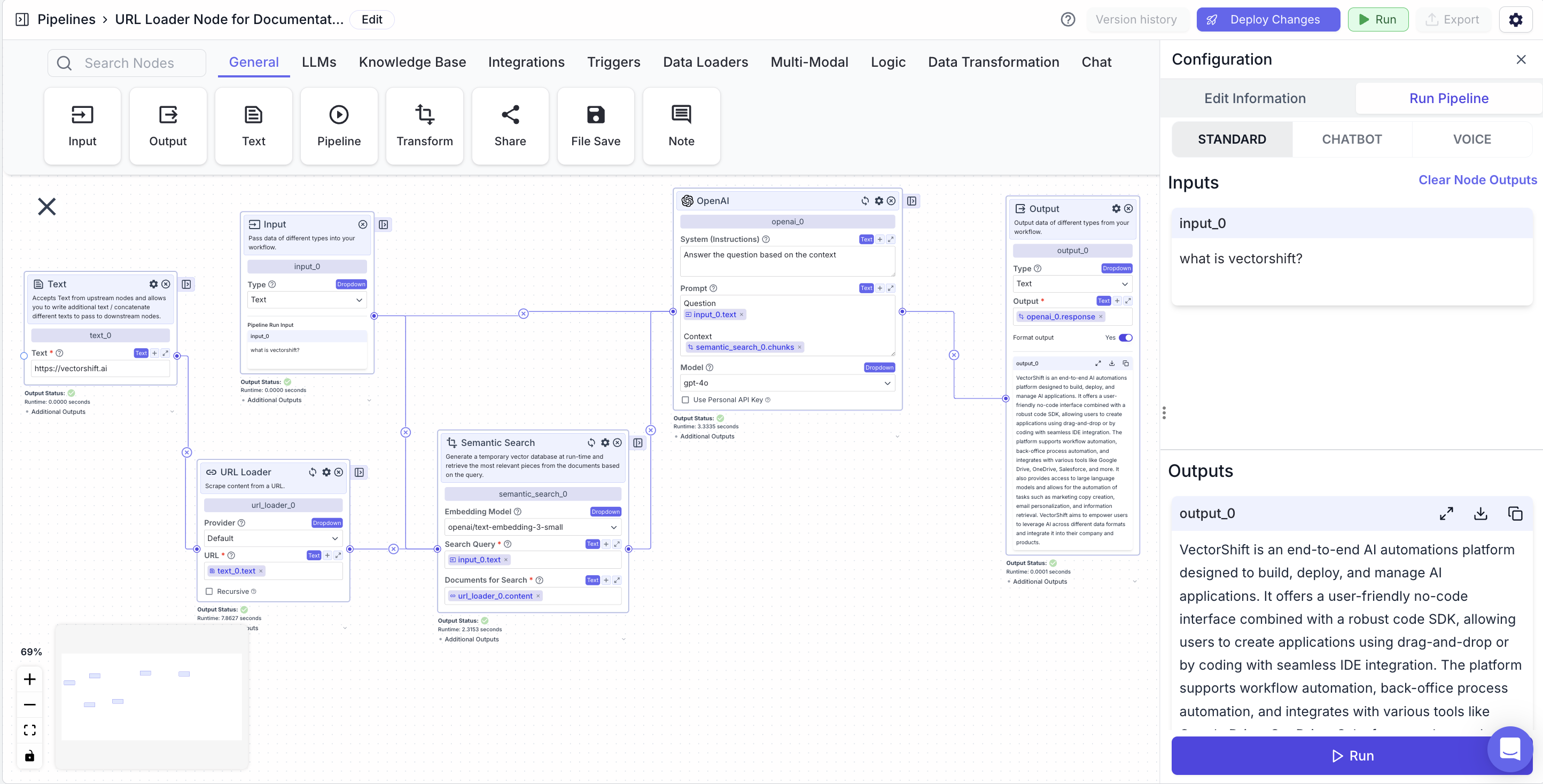
The below example is a pipeline which answers questions about on the contents of a website (example is with VectorShift’s website).- Input Node: The query about the website.
- Text Node: The URL for the website.
- Scrape URL node: Scrape the website URL
- URL:
{{text_0.text}}
- URL:
- Semantic Search Node: Find semantically similar chunks to a question (input node) based on a website (Scrape URL node).
- Search Query:
{{input_0.text}} - Documents for Search:
{{url_loader_0.content}}
- Search Query:
- LLM Node: Answer a user query (input node) based on relevant information (semantic search node).
- Prompt:
{{input_0.text}} and {{semantic_search_0.chunks}}
- Prompt:
- Output Node: Display the LLM’s response.
- Output:
{{openai_0.response}}
- Output: