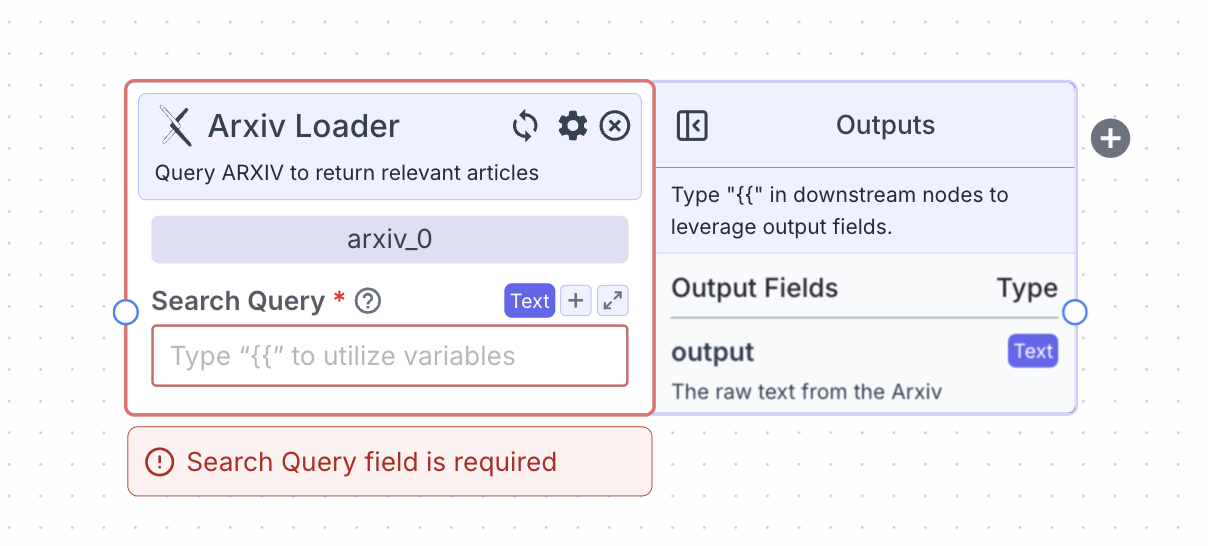
Node Inputs
- Search Query: The query text to search Arxiv
- Type:
Text
- Type:
Node Parameters
In the gear:- Chunk Text: Chunk the articles returned
- Chunk Size (if Chunk Text is set to True): The size of each chunks in tokens (1 token = 4 characters; default is 512 tokens)
- Chunk Overlap (if Chunk Text is set to True): The number of tokens of overlap between chunks (default is 0 tokens)
Node Outputs
- Output: The text from the relevant article(s)
- Type:
Text - Example usage:
{{arxiv_0.output}}
- Type:
Considerations
- Click on the “+” button on the right of the node to create and connect the node to a semantic search node to enable semantic search on the articles.
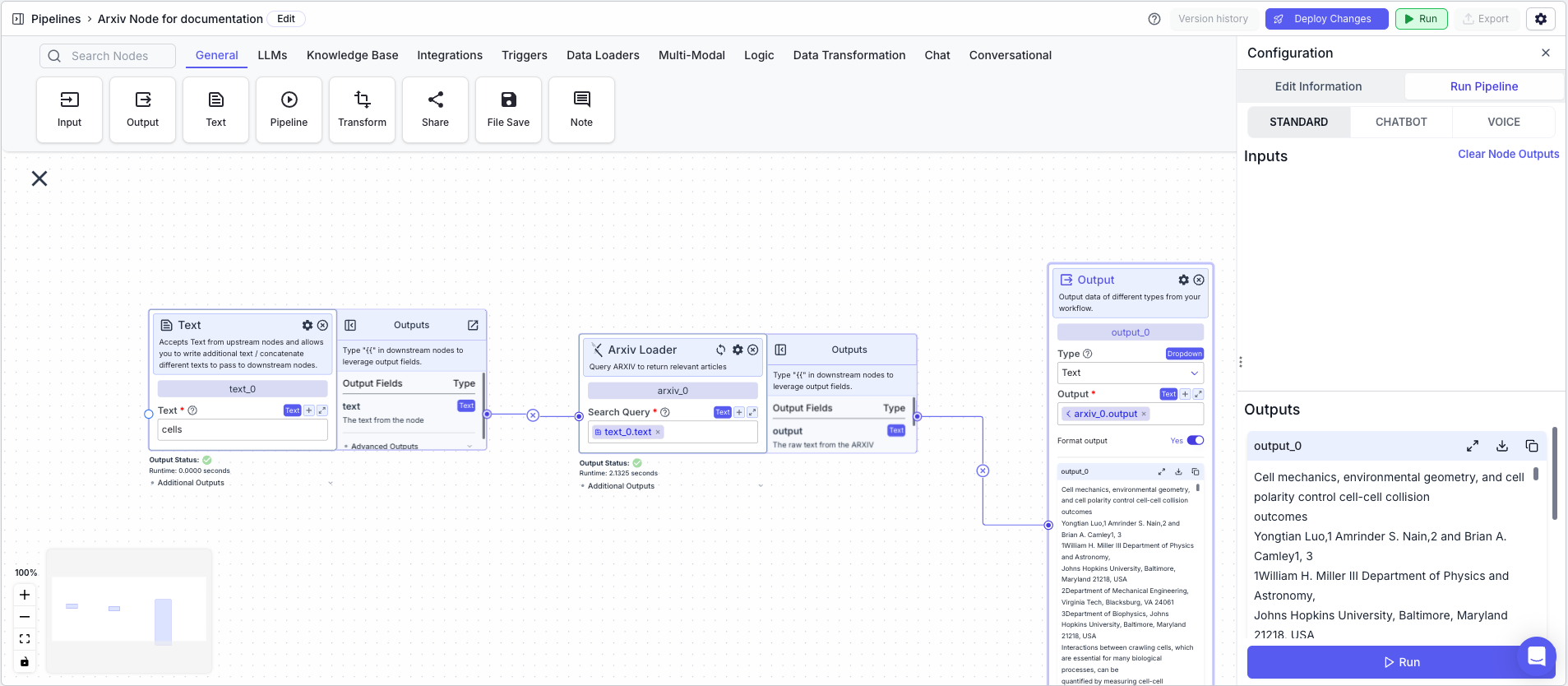
Example
The below example shows a pipeline that returns relevant Arxiv articles based on a search query.- Text Node: Contains the search query
- Arxiv Node: Returns relevant Arxiv articles based on a query
- Search Query:
{{text_0.text}}
- Search Query:
- Output Node: Displays the articles
- Output:
{{arxiv_0.output}}
- Output: