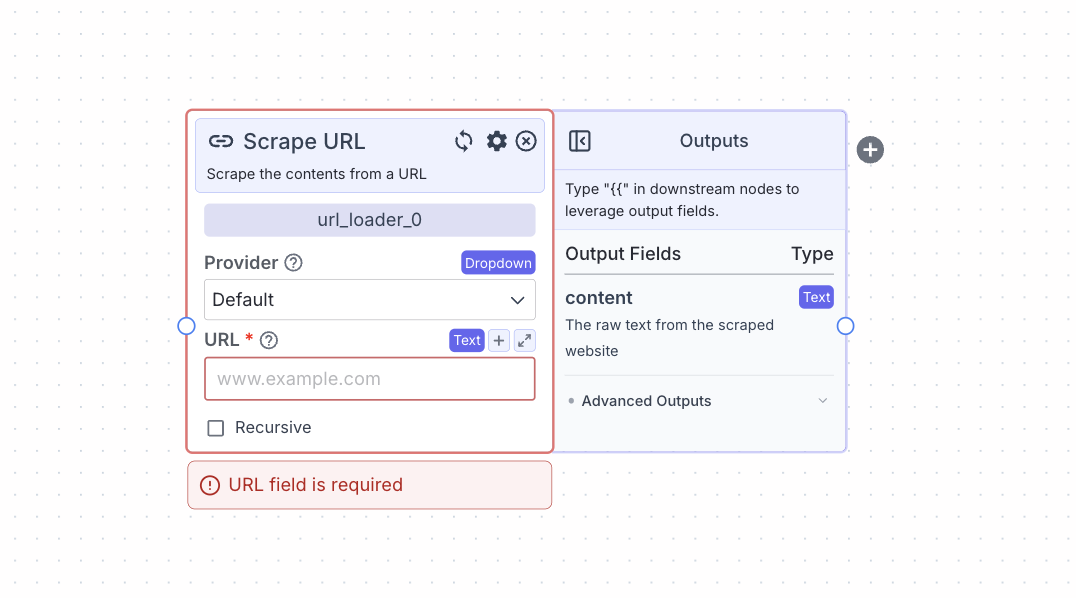
Node Inputs
- URL: The URL of the webpage you want scraped
- Type:
Text
- Type:
Node Parameters
On the face of the node:- Provider: The provider you want to use for scraping. The available providers are: Default (Combination of multiple providers), Jina and Apify.
- Recursive: This will enable the recursive scraping of URLs that have the same base URL. For example, https://vectorshift.ai/ and https://vectorshift.ai/enterprise all have the same based URL of https://vectorshift.ai/.
- URL Limit (if Recursive is set to true): The maximum limit for number URLs to scrape in recursion.
- Use Personal Api Key: This allows you to enter an API key (note APIFY requires API key).
- AI Enhance Content: Content from the website will be passed to an LLM to clean it up.
Node Outputs
- Content: The raw text from the website
- Type:
Text - Example usage:
{{url_loader_0.content}}
- Type:
Considerations
- Click on the “+” button on the right of the node to create and connect the node to a semantic search node to enable semantic search on the content.
- Do not share your API key with someone that you do not trust.
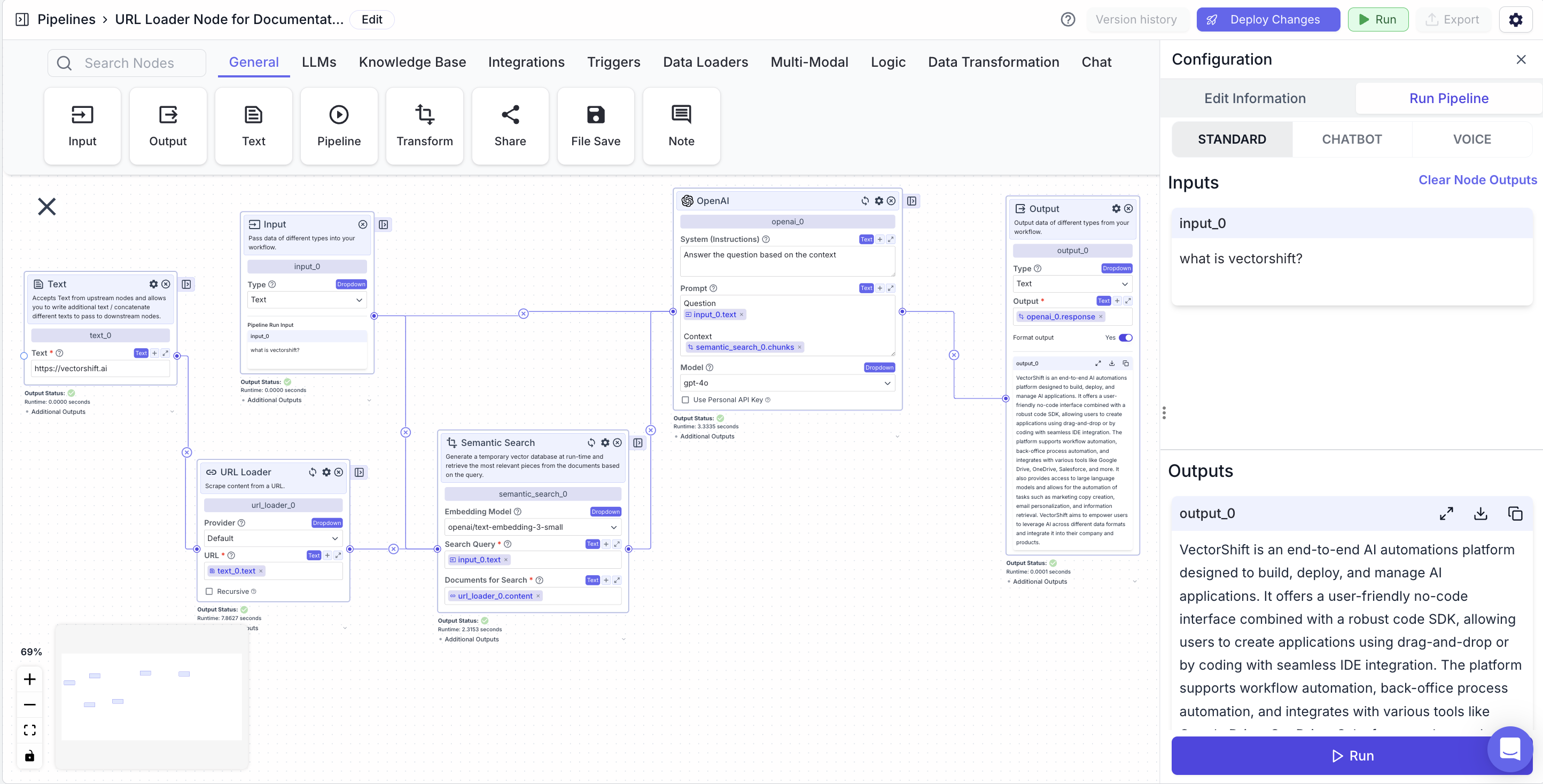
Example
The below example is a pipeline which answers questions about on the contents of a website (example is with VectorShift’s website).- Input Node: The query about the website.
- Text Node: The URL for the website.
- Scrape URL node: Scrape the website URL
- URL:
{{text_0.text}}
- URL:
- Semantic Search Node: Find semantically similar chunks to a question (input node) based on a website (Scrape URL node).
- Search Query:
{{input_0.text}} - Documents for Search:
{{url_loader_0.content}}
- Search Query:
- LLM Node: Answer a user query (input node) based on relevant information (semantic search node).
- Prompt:
{{input_0.text}} and {{semantic_search_0.chunks}}
- Prompt:
- Output Node: Display the LLM’s response.
- Output:
{{openai_0.response}}
- Output: