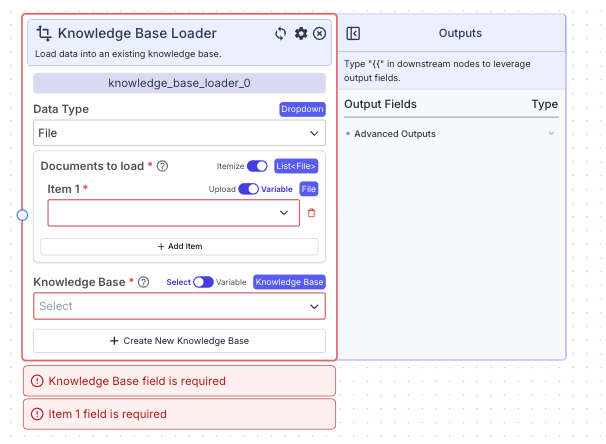
Node Inputs
- Knowledge Base: Select the knowledge base you would like to query.
- Type:
KnowledgeBase
- Type:
- Select: You can select from the dropdown a Knowledge Base in created in VectorShift platform.
- Variable: You can pass in a variable containing reference to the Knowledge Base you want to select.
- Documents to load: The file to be added to the selected Knowledge Base. Note: to convert text to file, use the Text to File node.
- Type:
List<File>
- Type:
- URL to load: The raw URL link (e.g., https://vectorshift.ai/)
- Type:
Text
- Type:
Node Parameters
If Data Type is URL:- Loader Type: The type of URL loader you want to use. The available loaders are URL, Wikipedia Query, Youtube URL, Arxiv Query and Repository URL. The default value is URL.
- Recursive: Scrape sub-pages of the provided link.
- Re-scrape Frequency: The frequency that the URL will be re-scraped. The available options are Never, Hourly, Daily, Weekly and Monthly. The default value is Never.
Node Outputs
The knowledge base loader node does not have any node outputs.Example
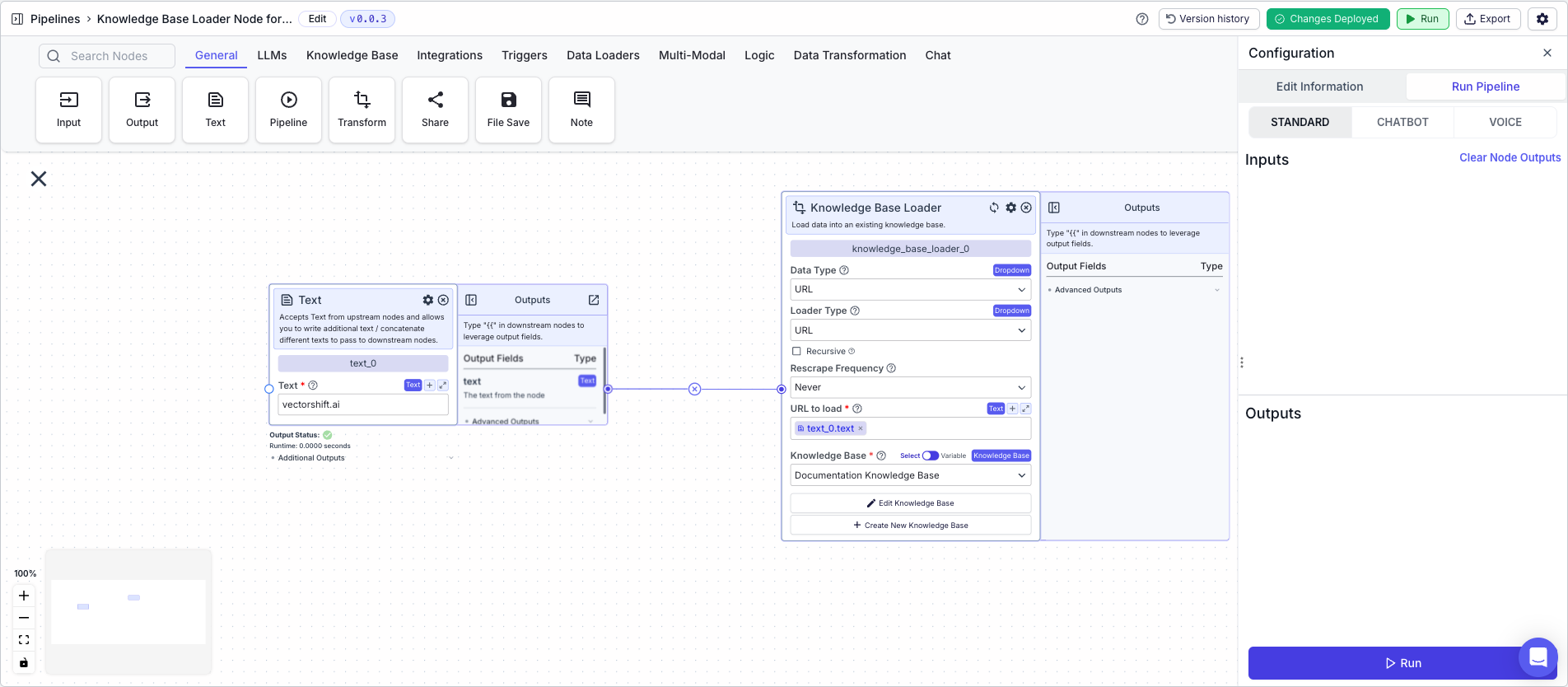
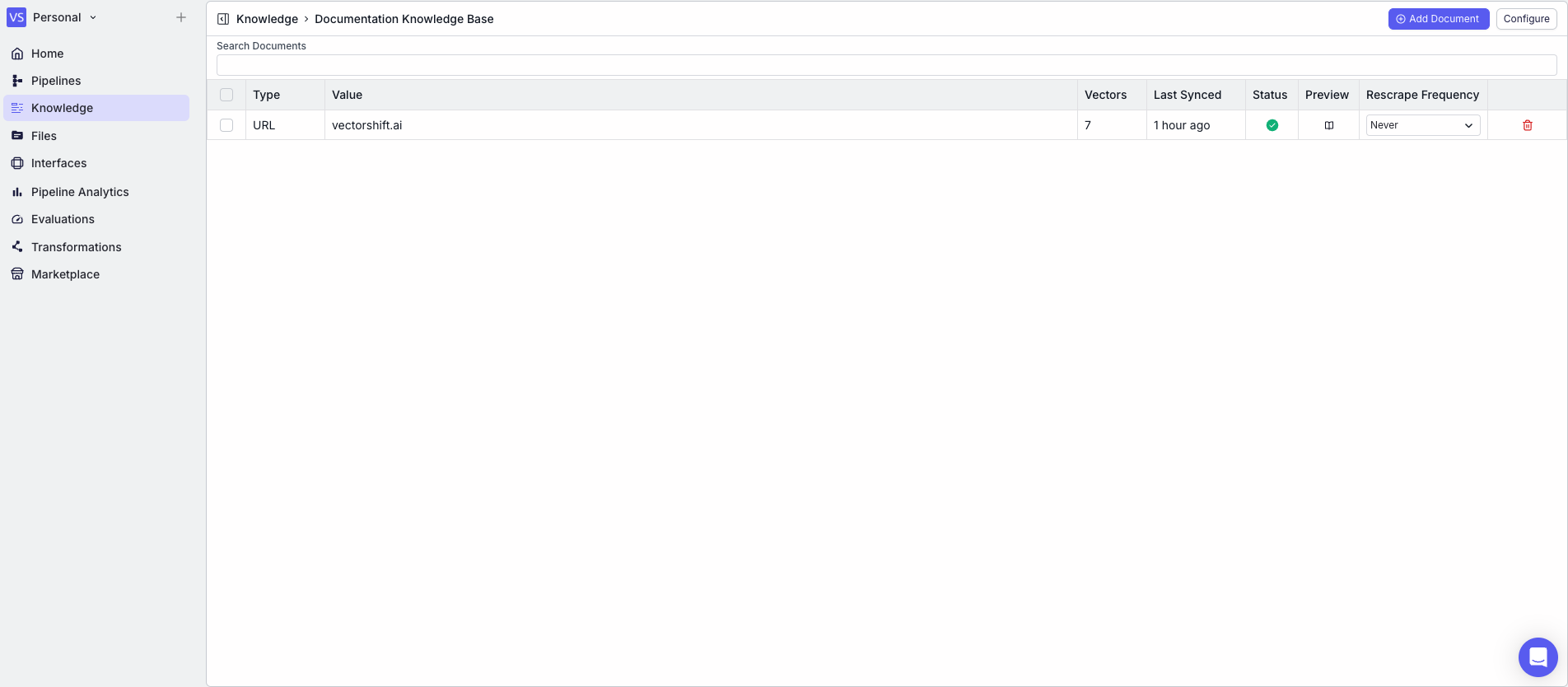
The below example shows a pipeline that loads content from vectorshift.ai into a knowledge base.- Text Node: Contains the URL “vectorshift.ai”
- Knowledge Base Loader Node:
- Knowledge Base: Select the knowledge base you want to load the data into from the “Knowledge Base” drop down
- Data Type:
URL - URL to load:
{{text_0.text}}