Use this node from the SDK
Add it in Python with
pipeline.add(name="...").browser_extension(...). See the SDK reference.Core Functionality
- Captures the current browser page’s content, URL, links, HTML, and screenshot via the VectorShift Chrome Extension
- Feeds captured page data into a workflow as output fields that downstream nodes can consume
- Requires the VectorShift Chrome Extension to be installed and the workflow to be deployed
Tool Inputs
This node has no configurable input fields. All data is captured automatically from the active browser page when the workflow is triggered via the Chrome Extension.Show on VectorShift Chrome Extension— Toggle. Default:on. Controls whether this workflow appears in the VectorShift Chrome Extension after deployment.
Tool Outputs
page_content— Text. The text content extracted from the current page.url— Text. The URL of the current page.page_urls— List<Text>. All URLs (links) found on the current page.screenshot— Image. A screenshot of the current page.page_html— Text. The raw HTML source of the current page.
- Workflows
Overview
In workflows, the Browser Extension node acts as an entry point that captures live web page data when a user triggers the workflow from the Chrome Extension. It outputs the page’s text content, URL, links, screenshot, and HTML — making it easy to build automations that process any page a user is viewing. Use it to power on-demand web research, document extraction, or monitoring workflows triggered directly from the browser.Use Cases
- Extract key financial metrics from an earnings report page and route them into a structured spreadsheet workflow
- Capture a screenshot of a live trading dashboard and send it to a Slack channel via a notification node
- Summarize a lengthy regulatory filing or legal document open in the browser into a concise brief
- Pull all outbound links from a competitor’s product page for competitive intelligence analysis
- Grab the HTML of a vendor invoice page and feed it into a data extraction workflow
How It Works
Step 1: Add the Browser Extension Node
In the workflow canvas, click the Start tab in the node palette and click Browser Extension. Drag it onto the canvas.
Step 2: Review Settings
The node has one setting:Show on VectorShift Chrome Extension. This toggle is on by default and controls whether the workflow is available in the Chrome Extension after deployment. Leave it on for the workflow to appear in the extension.Step 3: Connect Downstream Nodes
Connect the output handles (page_content, url, page_urls, screenshot, page_html) to downstream nodes. For example, connect page_content to an LLM node for summarization, or screenshot to an image processing node.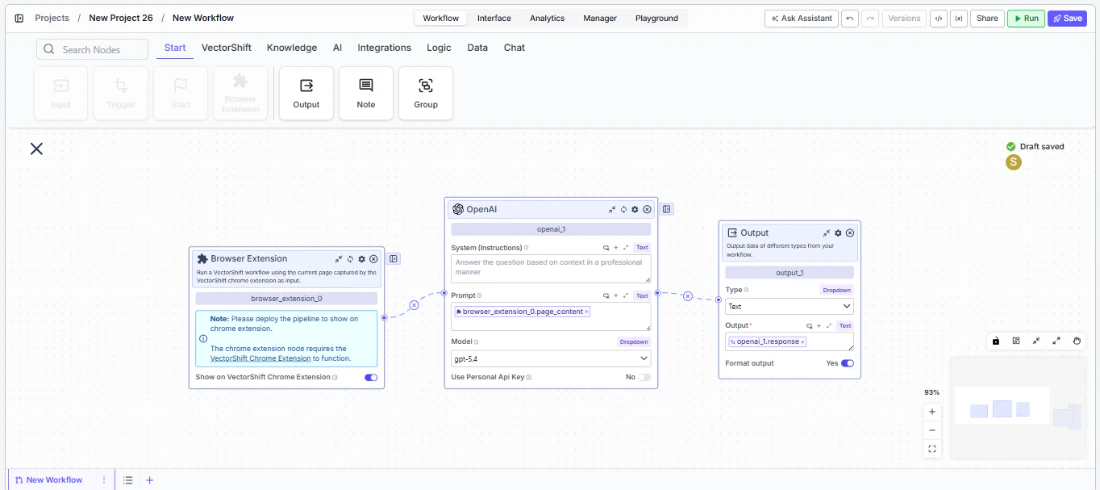
Step 4: Deploy the Workflow
The node displays a note: “Please deploy the workflow to show on chrome extension.” Save and deploy the workflow so it becomes available in the Chrome Extension.Step 5: Trigger from the Browser
Open the VectorShift Chrome Extension on any web page. Select the deployed workflow and run it. The node automatically captures the current page’s data and passes it to the workflow.Settings
| Setting | Type | Default | Description |
|---|---|---|---|
Show on VectorShift Chrome Extension | Toggle | On | Whether the workflow appears in the Chrome Extension after deployment. |
Best Practices
- Deploy before testing. The Browser Extension node only works after the workflow is deployed — running it on the canvas without deployment will not capture browser data.
- Use
page_contentfor text analysis. For summarization, extraction, or classification tasks,page_contentprovides clean text without HTML markup. - Use
page_htmlfor structured extraction. When you need to parse specific elements (tables, forms, metadata), use the raw HTML output with a transformation or code node. - Combine
screenshotwith image-to-text. For pages that render content as images (charts, infographics), pipe the screenshot into an Image to Text node. - Filter
page_urlsfor targeted crawling. Use a Filter List node downstream to narrow the captured URLs to specific domains or patterns before further processing.
Related Templates
Webpage Customer Support Agent
Provides real-time customer support directly embedded within a website interface.
Webpage Compliance Agent
Scans and evaluates webpage content for regulatory and legal compliance issues.