How to use an LLM
To use an LLM, you must provide the following inputs:- System Prompt: instruct how the LLM should behave in the system prompt within the LLM node or write it in a text box and connect it to the “System” input edge. Reference data sources you use in the Prompt within System (Answer the User Question using Context)
- Prompt: define variables using double curly braces (open the variable builder by typing :
{{in any text field)
LLM Settings
System and Prompt
Some models (e.g., OpenAI) are trained to take two inputs, a “system” prompt that contains instruction for the model to follow and a “prompt” input with various data sources (e.g., the user message, context, data sources, etc.). Other models (e.g., Gemini) have one singular prompt where you place both the instructions and the data sources.Token Limits
Each model has a limit max number of input and output tokens. To adjust the limit for a particular model you can alter the max tokens parameter.You cannot increase the max tokens beyond the maximum supported for a particular model.
This setting is found in the gear on the LLM node.
Streaming
To stream output, click on the gear and then check “Stream Response”. This setting is found in the gear on the LLM node.Citations
You can display the sources the LLM uses by checking off “Show Sources” in the gear. This setting is found in the gear on the LLM node.JSON Response
To have the model return a structured JSON output rather than pure text check the “Json output” box. This setting is found in the gear on the LLM node. When using Json mode you can optionally provide the Json Schema. This will help the LLM know which json fields to generate. For example if I want the output json to have a “temperature” field which is an integer and a unit field which is either Celsius or Fahrenheit I can define the schema as follows:Temperature
Temperature controls the diversity of LLM generation. You can adjust the temperature settings for your models. To have more diverse or creative generations increase the temperature. To have more deterministic response decrease the temperature. This setting is found in the gear on the LLM node.Top P
The TopP parameter constrains how many tokens the LLM considers for generation at each step. For more diverse responses increase top p towards a maximum value of 1.0. This setting is found in the gear on the LLM node.AI Model Costs
Model usage is billed based on the number of tokens that you use, both in the model input and the tokens generated in the model output. One token is equal to 4 characters.Azure LLM
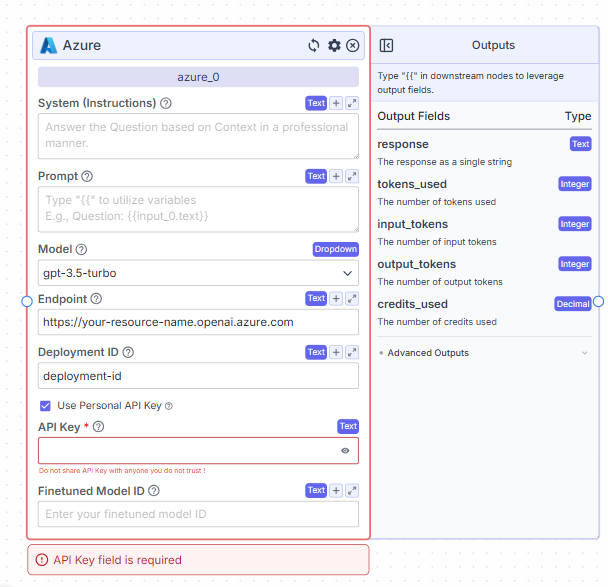
gpt-3.5-turbo, or any other model from Azure OpenAI.
To connect with your own model:
To get started, you’ll need to have access to an Azure OpenAI resource and a deployed model (for example, gpt-3.5-turbo).The Endpoint field is where you enter the base URL of your Azure OpenAI resource. It usually looks like
https://your-resource-name.openai.azure.com. Make sure you do not include a trailing slash.
In the Deployment ID field, enter the name of the deployment you’ve configured in your Azure OpenAI service. This must exactly match the ID used in Azure.
If you’re using a personal API key, check the Use Personal API Key option. Then, paste your Azure API key into the API Key field. This key is available in the Azure portal under your resource’s Keys and Endpoint section. Note that this field is required when using a personal key, and you should not share this key with anyone you do not trust.
The Finetuned Model ID field is optional. You only need to fill it out if you’re working with a fine-tuned version of the model.
A common configuration might look like this: the model is set to gpt-3.5-turbo, the endpoint is https://my-openai-resource.openai.azure.com, and the deployment ID is gpt-35-turbo. The prompt could be something like Answer the following: {{input_0.text}}.
Some common issues to watch for include leaving the API Key field blank, using the wrong deployment ID, or including a trailing slash in the endpoint URL. Always double-check that all values exactly match your Azure setup.
For more information, refer to the official Azure OpenAI documentation at [learn.microsoft.com](https://learn.microsoft.com/en-us/azure/ai-services/openai/reference).
Custom LLMs
Want to connect to a specialized model provider or a locally hosted LLM? Use the custom LLM node. We have support for sending requests to models that are compatible with the OpenAI Chat API format. You can use models from your own accounts with LLM providers such as TogetherAI and Replicate. The custom LLM node requires the following parameters:modelapi_keybase_url
Local Models
Models hosted locally on your computer are good for prototyping, experimenting with new models and cost savings. You can access your local models be setting up a connection to a locally running LLM server. Make sure to find a secure way to forward your locally running server’s port to the internet. LM Studio Follow the instructions to start a local LM studio server. The standard API key for LM studio islm-studio
Ollama
Start a local LLM server using the Ollama CLI.
Prompt Engineering Guidelines
Be as specific as possible - if the output should be one sentence or if the output should be in the first person, include the instructions in the text block connected to the system prompt. Within the system prompt, you can also mention things like:- The tone you want the model to use (e.g., Respond in a professional manner).
- Data sources and how the model should use them (e.g., Use datasource X when the question is related to sales; use datasource Y when the question is related to customer support).
- Specific information related to your company / situation that the model can reference (e.g., calendly link)
- Specific text that you want the model to output in certain situations (e.g., if you are unable to answer the question, respond with “I am unable to answer the question”).
- What type of reasoning to use (here - it is important to think through step by step how you would actually perform the action. You then, want to encode this into the system prompt).