Node Inputs
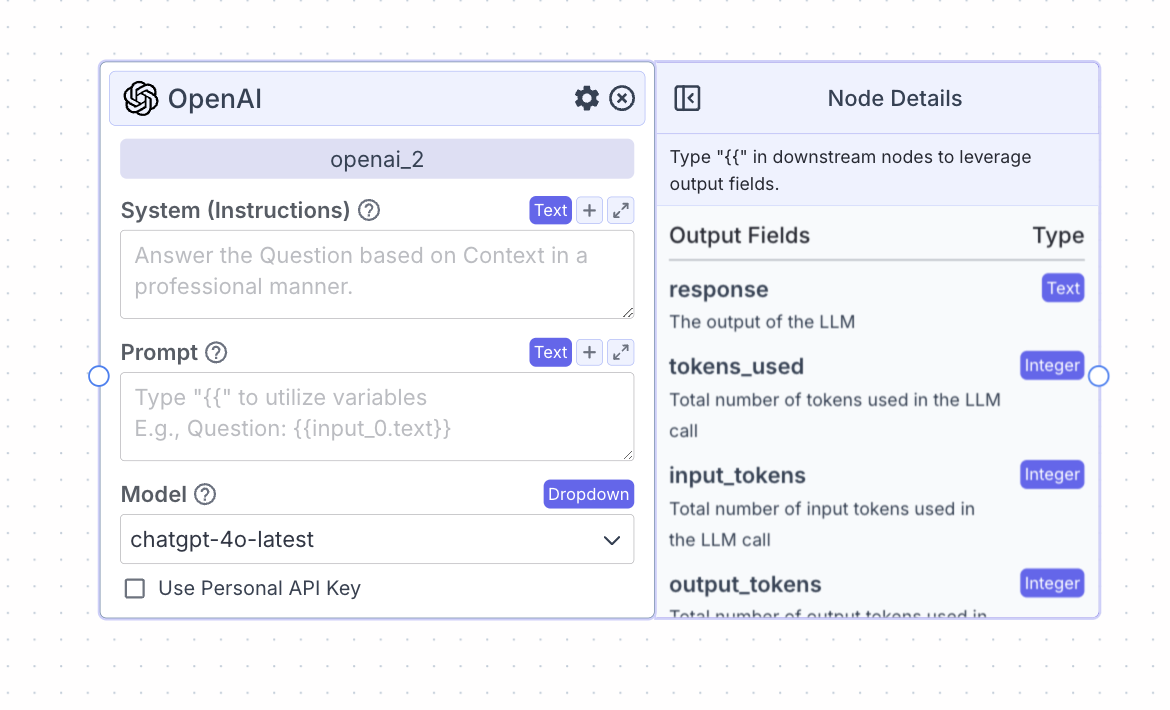
- System (Instructions): Specify how you would like the LLM to respond (e.g., the style). It is common to specify here how the LLM should utilize the data received in Prompt.
- Type:
Text
- Type:
- Prompt: Provide the data the LLM should consider. Type
{{to open the variable builder.- Type:
Text
- Type:
Node Parameters
On the face of the node:- Model: Select the model to use from the provider
- Provider: Change the provider of the LLM.
- Max tokens: The maximum number of output tokens for each LLM run.
- Temperature: The diversity of the LLM generation. To have more diverse or creative generations, increase the temperature. To have more deterministic response, decrease the temperature.
- Top P: The Top P parameter constrains how many tokens the LLM considers for generation at each step. For more diverse responses increase top p towards a maximum value of 1.0. This setting is found in the gear on the LLM node.
- Stream Response: Check to have responses from the LLM stream. Ensure to change the Type on the output node to “Streamed Text”.
- JSON Output: Check to to have the model return a structured JSON output rather than pure text.
- Show Sources: Display sources of documents used from the knowledge base.
- Show Confidence: Show the confidence level of the LLM’s answer.
- Toxic Input Filtration: Filter out toxic content; if the LLM receives a toxic message, the LLM will respond with a respectful one.
- Detect PII: Detect and remove PII from being sent to the LLM.
Node Outputs
- Response: The output of the LLM
- Type:
Text(orStream<Text>if streaming is enabled) - Example usage:
{{openai_0.response}}
- Type:
- Tokens_used: The total number of tokens used
- Type:
Integer - Example usage:
{{openai_0.tokens_used}}
- Type:
- Input_tokens: The total number of input tokens used
- Type:
Integer - Example usage:
{{openai_0.input_tokens}}
- Type:
- Output_tokens: The total number of output tokens used
- Type:
Integer - Example usage:
{{openai_0.output_tokens}}
- Type:
- Credits_used: The total number of VectorShift AI credits used
- Type:
Decimal - Example usage:
{{openai_0.credits_used}}
- Type:
Example
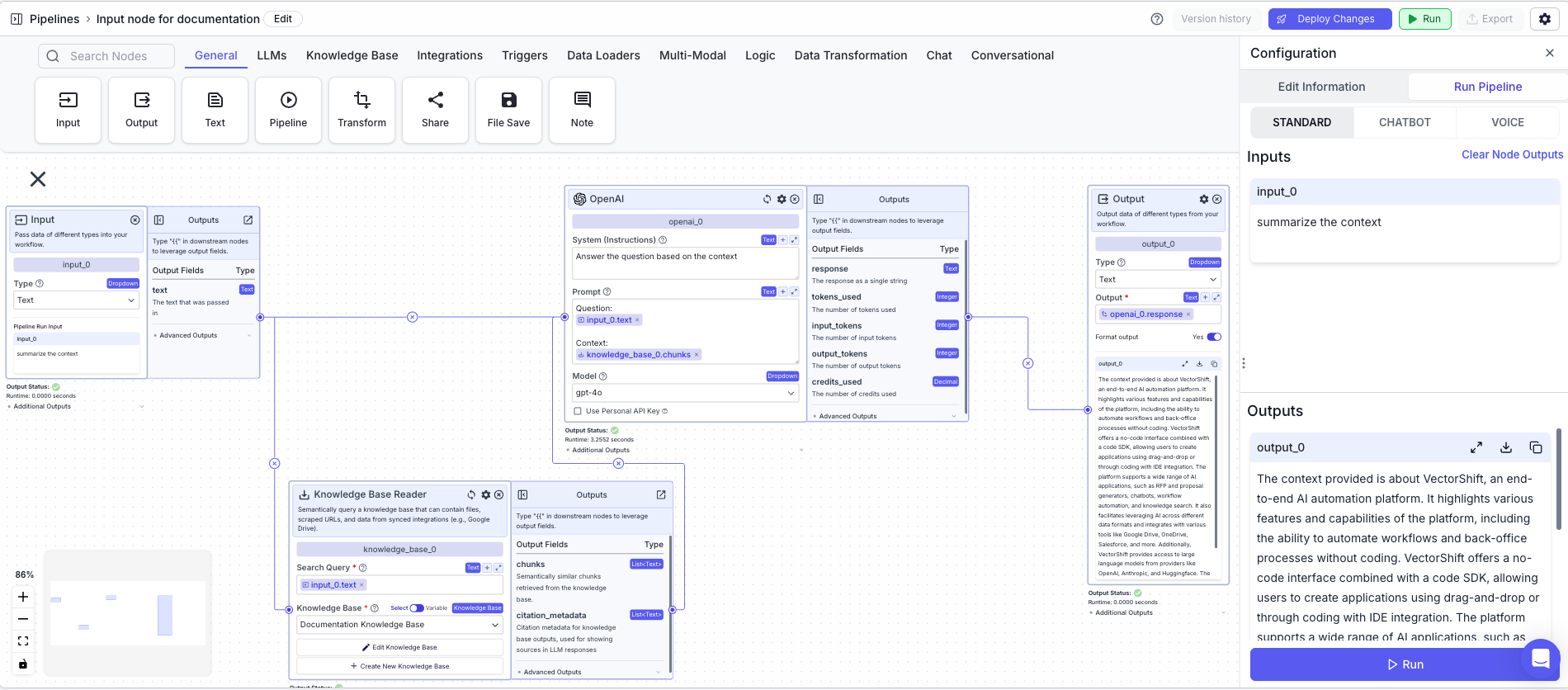
The below example is a pipeline for chatting with a knowledge base. The LLM is used to generate the response to the user question.- Input Node: Represents the user message
- Knowledge Base Reader Node: Queries the knowledge base semantically
- Search Query:
{{input_0.text}}
- Search Query:
- LLM Node: Responds to the user question
- System (Instructions):
Answer the question based on the context. - Prompt:
Question: {{input_0.text}} Context: {{knowledge_base_1.chunks}}
- System (Instructions):
- Output Node: Displays the response
- Output:
{{openai_0.response}}
- Output: