Node Inputs
- Text: The text for chunking
- Type:
Text
- Type:
Node Parameters
In the gear:- Chunk Size: The size of each chunk of text in number of tokens. One token = 4 characters. The default value is
512 tokens. The value ranges from1to4096.- Type:
Text
- Type:
- Chunk Overlap: The overlap of each chunk text in number of tokens. One token = 4 characters. The default value is
0. The value ranges from0to4096.- Type:
Text
- Type:
- Chunk Strategy: Strategy for grouping segmented text into final chunks.
sentence: groups sentences,markdown: respects markdown structure (headers, code),dynamic: optimizes breaks for size using chosen segmentation method (see below). The default option isMarkdown.- Type:
Dropdown
- Type:
Dynamic is selected as the chunk strategy:
- Segmentation Method: The method to break text into units before chunking.
words: splits by word,sentences: splits by sentence boundary,paragraphs: splits by blank line/paragraph. The default option iswords.- Type:
Dropdown
- Type:
Node Outputs
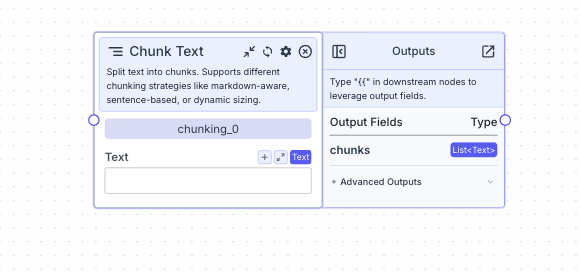
- Chunks: The chunked text in a list
- Type:
List<Text> - Example usage:
{{chunking_0.chunks}}
- Type:
Example
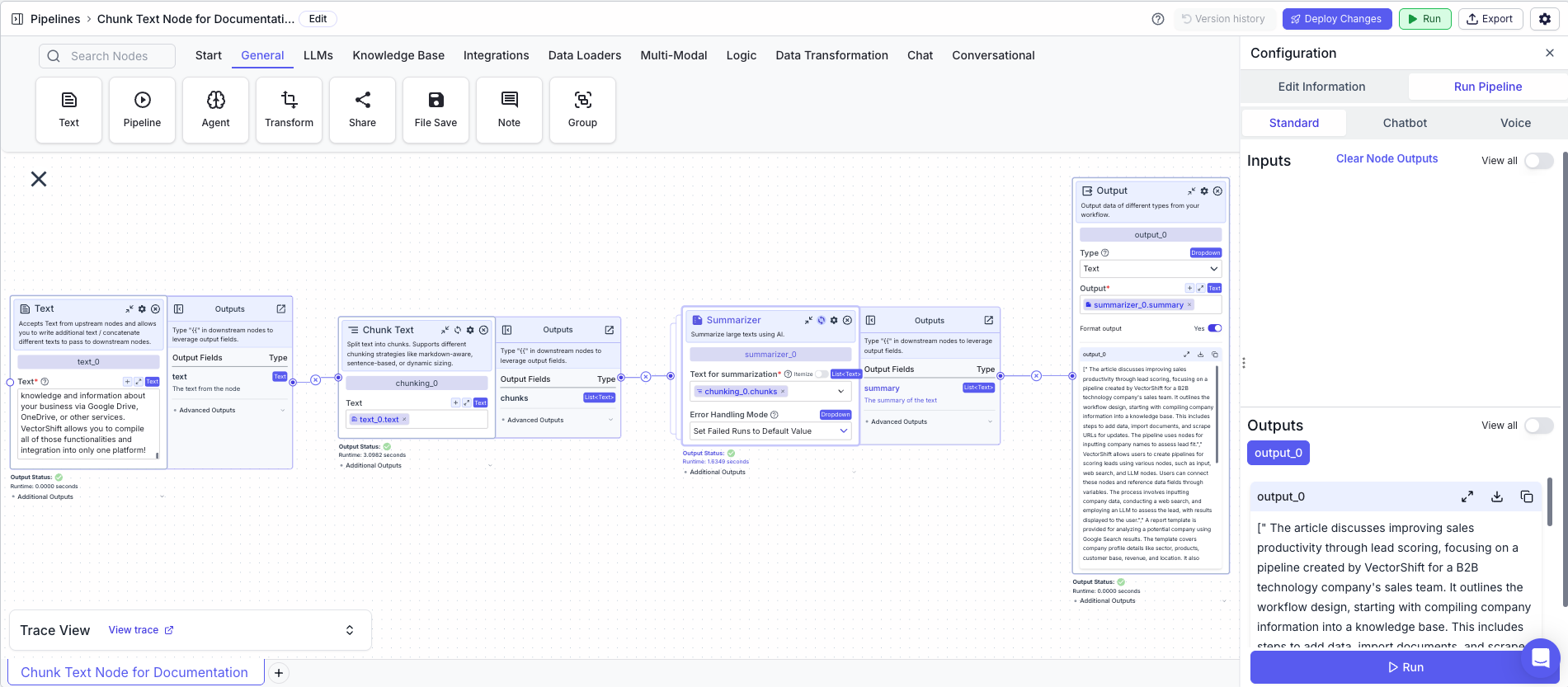
The below example shows a pipeline that takes a blog, chunks it into a list of text, and summarizes each chunk.- Text Node: Contains the text
- Text:
The text from the blog
- Text:
- Chunk Text Node: Splits the text into chunks of text based on the chunk size and overlap
- Text:
{{text_0.text}}
- Text:
- Summarizer Node: Summarizes each chunk in the list (list mode applies the operation, in this case, summarization, onto each item in the list)
- List Mode:
True - Text for summarization:
{{chunking_0.chunks}}
- List Mode:
- Output: Display the list of summaries
- Output:
{{summarizer_0.summary}}
- Output: