- If toggle is on Upload: Upload a file by clicking the upload button
- If toggle is on Variable: Reference image files from other nodes
Node Inputs
- System (Instructions): Tell the AI model how to utilize the data (e.g., extract all the text from the image) or behave.
- Type:
Text
- Type:
- Prompt: The data that is sent to the LLM.
- Type:
Text
- Type:
- Image: The image to convert to text
- Type:
Image
- Type:
Node Parameters
On the face of the node:- Provider: Provider of the AI model you want to use. The default provider is OpenAI.
- Model: Specific model you want to use.
- Use Personal Api Key: This allows you to enter your API key.
- Max tokens: The maximum amount of input + output tokens the model will take in and generate per run (1 token = 4 characters). Note: different models have different token limits and the workflow will error if the max token is reached.
- Temperature: The diversity of the LLM generation. To have more diverse or creative generations, increase the temperature. To have a more deterministic response, decrease the temperature.
- Top P: The Top P parameter constrains how many tokens the LLM considers for generation at each step. For more diverse responses increase top p towards a maximum value of 1.0.
- Stream Response: Check to have responses from the LLM stream. Ensure to change the Type on the output node to “Streamed Text”.
- JSON Output: Check to to have the model return a structured JSON output rather than pure text.
Node Outputs
- Text: The text generated from the LLM.
- Type:
Text - Example usage:
{{ai_image_to_text_0.text}}
- Type:
- Tokens Used: The number of tokens used for the run
- Type:
Integer - Example usage:
{{ai_image_to_text_0.tokens_used}}
- Type:
Example
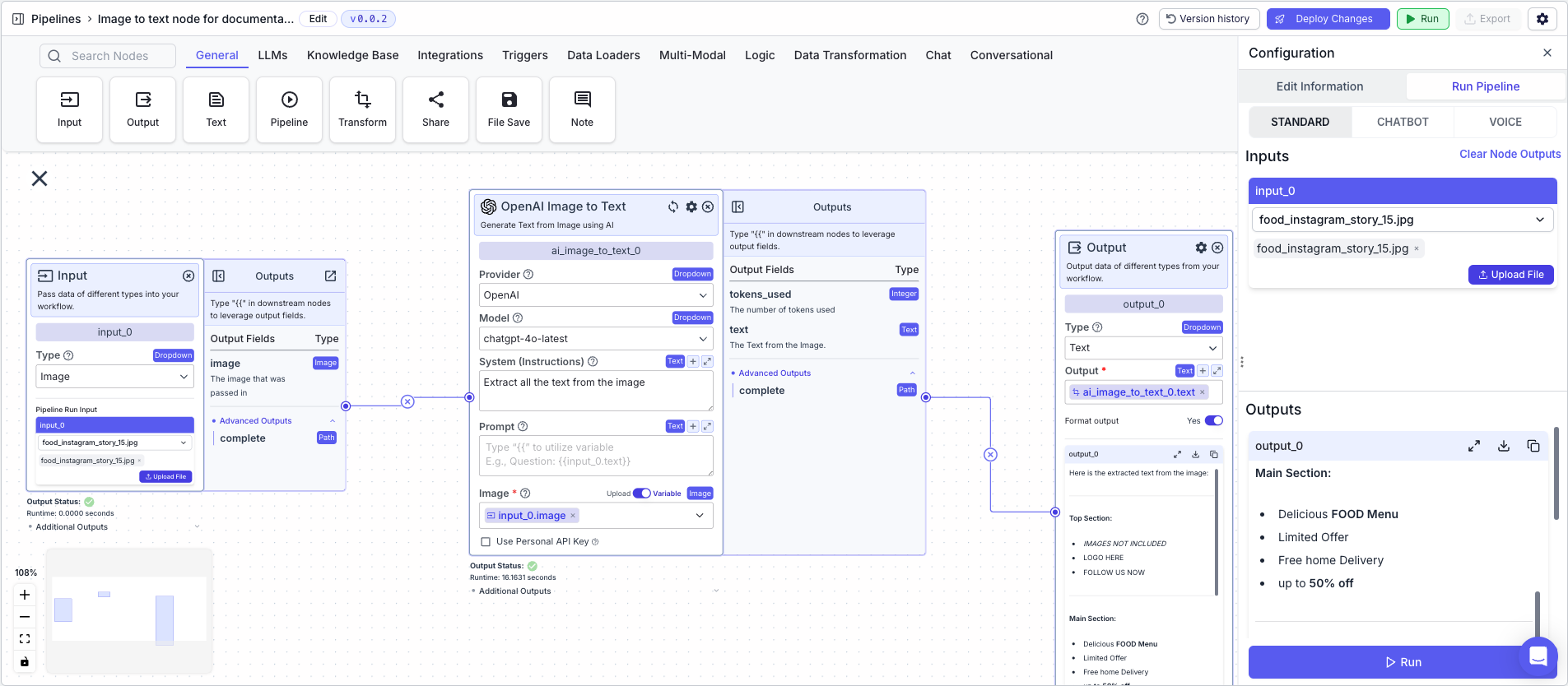
The below example shows a pipeline that takes an image of food menu and converts it to text.- Input Node: Contains the input image of food menu
- Image to Text Node: Converts the image to text
- System:
Extract all the text from the image - Image:
{{input_0.image}}
- System:
- Output: The text generated from the image
- Output:
{{ai_image_to_text_0.text}}
- Output: