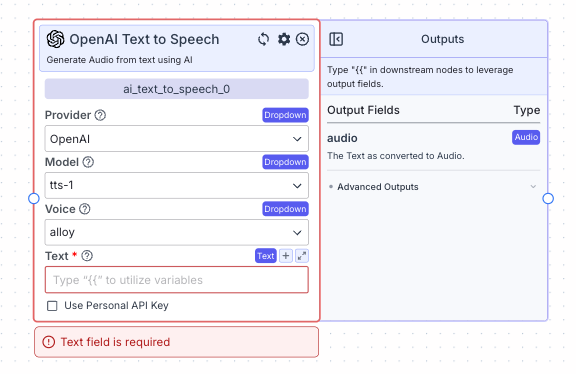
Node Inputs
- Text: The text to convert to audio
- Type:
Text
- Type:
Node Parameters
- Provider: Provider of the text to speech model you want to use. The default provider is OpenAI.
- Model: Specific model you want to use.
- Voice: The voice for the generated audio.
- Use Personal Api Key: This allows you to enter your API key.
Node Outputs
- Audio: The text converted to audio
- Type:
Audio - Example usage:
{{ai_text_to_speech_0.audio}}
- Type:
Example
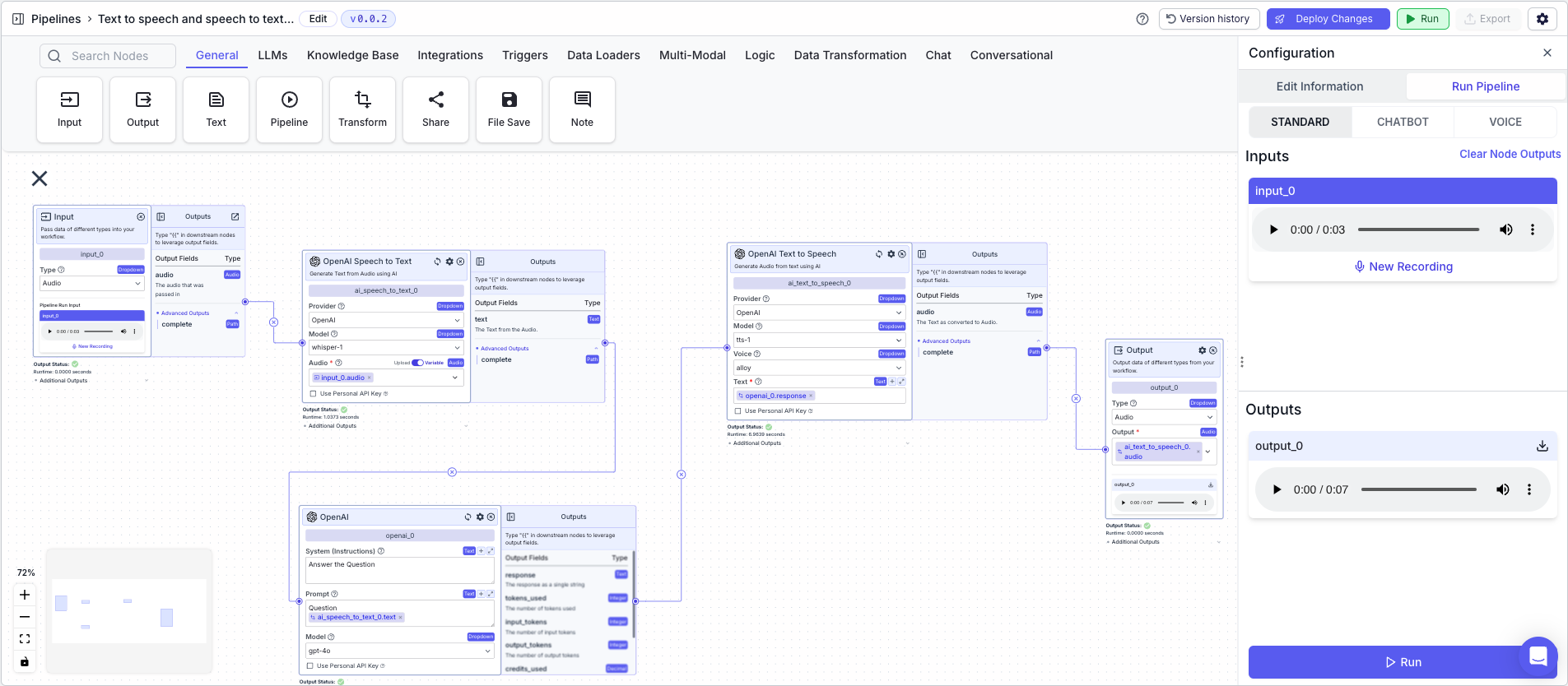
The below example shows a pipeline that takes audio input, converts it to text, processes it with an LLM, and converts the response back to audio.- Input Node: Contains the input audio (recorded through the VectorShift platform)
- Speech to Text Node: Converts the audio to text
- Audio:
{{input_0.audio}}
- Audio:
- LLM Node: Processes the text / Answers the user question
- Input:
{{ai_speech_to_text_0.text}}
- Input:
- Text to Speech Node: Converts the LLM response to audio
- Text:
{{openai_0.response}}
- Text:
- Output: The final audio response
- Output:
{{ai_text_to_speech_0.audio}}
- Output: